
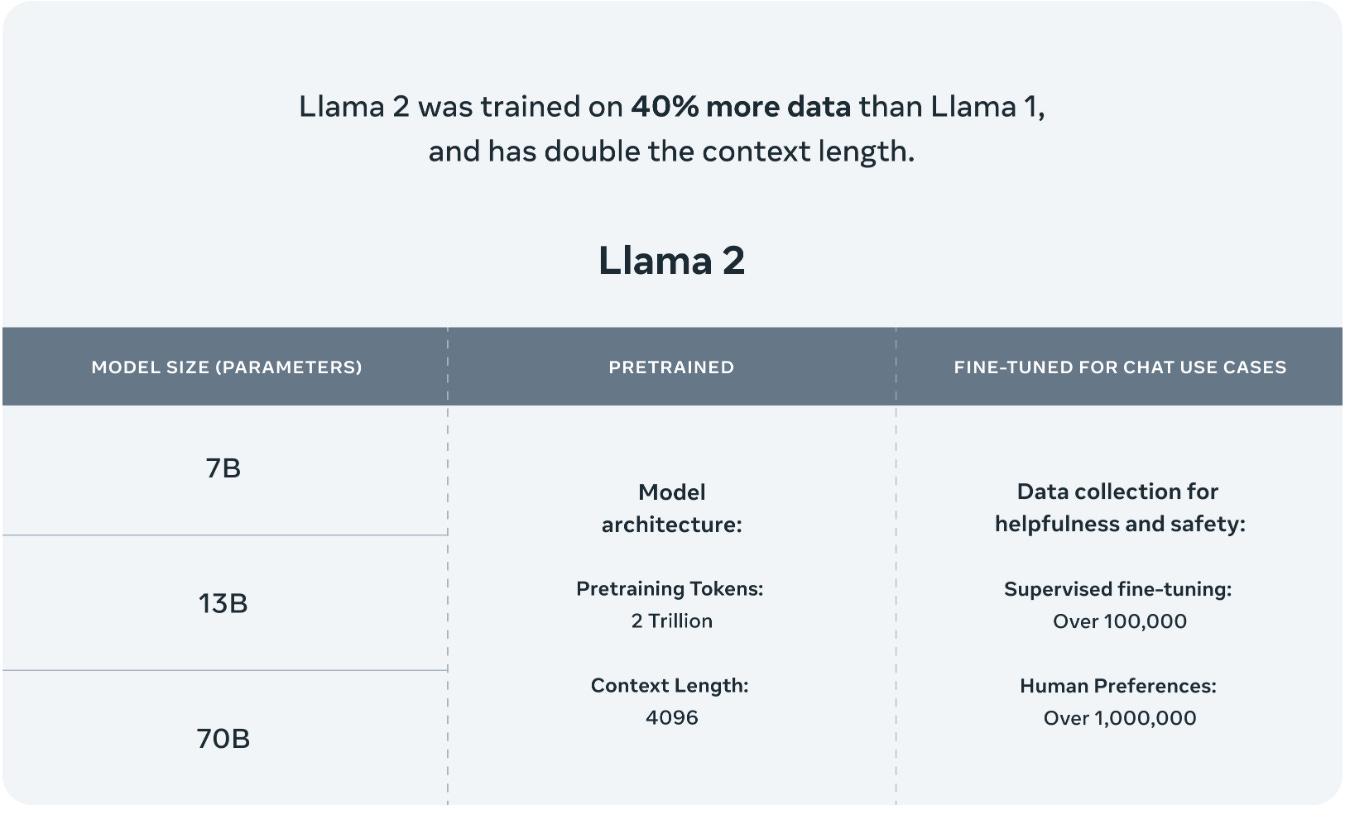
Context length settings for llama 2 models. Llama 2 pretrained models are trained on 2 trillion tokens and have double the context length than Llama 1. Contrary to GPT-4 which extended its context length during the fine-tuning process both Llama 2 and Llama 2. Introduction Llama 2 is a family of state-of-the-art open-access large language models released by. Llama 2 supports a context length of 4096 twice the length of its predecessor. On July 18th Meta published Llama2-70B-Chat A 70B parameter language model pre-trained. The model has an increased context length of 4K tokens than Llama 1 This allows it to retain more..
Lesswrong
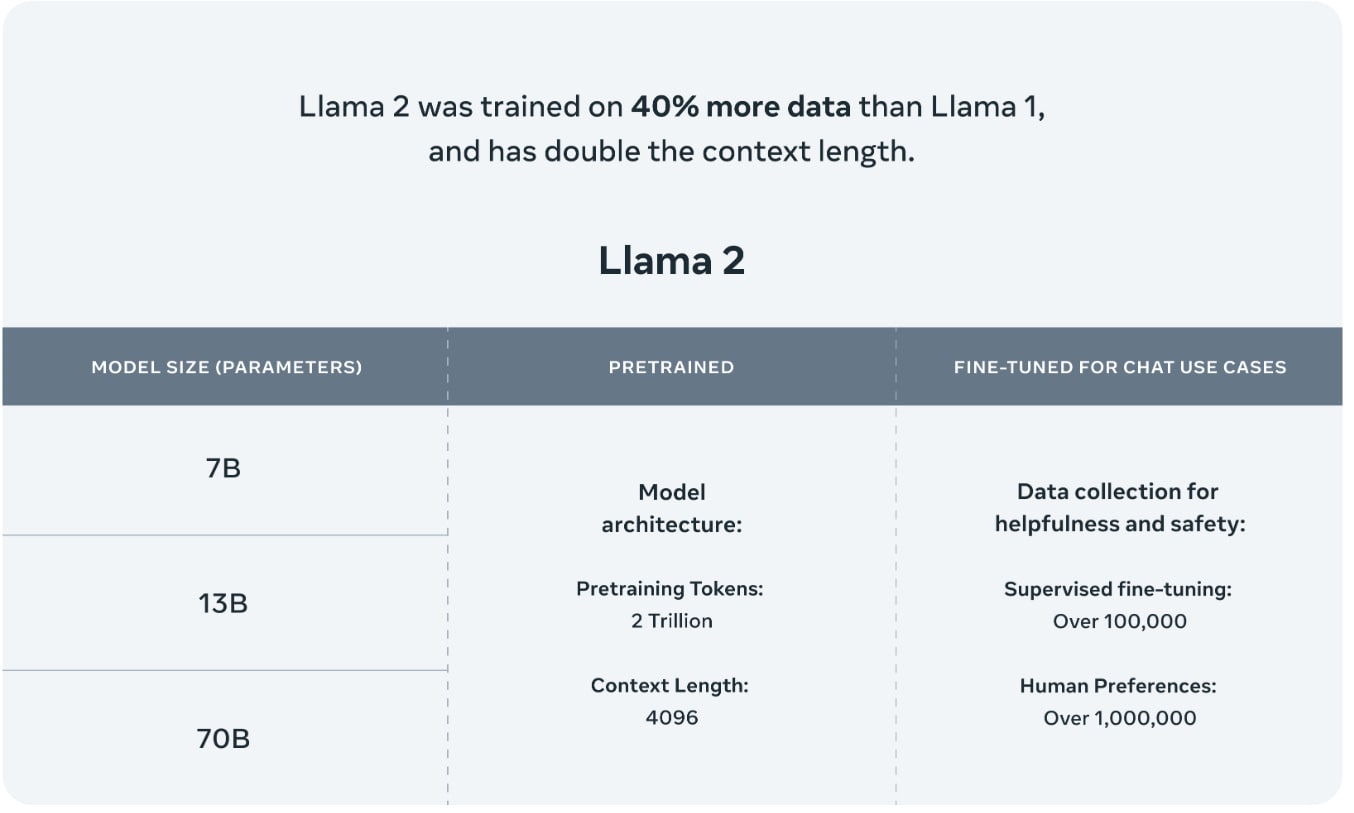
We have a broad range of supporters around the world who believe in our open approach to todays AI companies that have given early feedback and are excited to build with Llama 2 cloud. Llama 2 pretrained models are trained on 2 trillion tokens and have double the context length than Llama 1 Its fine-tuned models have been trained on over 1 million human annotations. Chat with Llama 2 70B Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your. Llama 2 is a family of pre-trained and fine-tuned large language models LLMs released by Meta AI in 2023 Released free of charge for research and commercial use Llama 2. Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned variations..
LLaMA-65B and 70B performs optimally when paired with a GPU that has a. If it didnt provide any speed increase I would still be ok with this I have a 24gb 3090 and 24vram32ram 56 Also wanted to know the Minimum CPU needed CPU tests show 105ts on my. Using llamacpp llama-2-70b-chat converted to fp16 no quantisation works with 4 A100 40GBs all layers offloaded fails with three or fewer Best result so far is just over 8. Llama 2 is broadly available to developers and licensees through a variety of hosting providers and on the Meta website Only the 70B model has MQA for more. Below are the Llama-2 hardware requirements for 4-bit quantization If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre after..
Lesswrong
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters We train our models on trillions of tokens and show that it is possible to train. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters On the series of helpfulness and safety..



Comments